sudo pico mcp_server5.py
from fastapi import FastAPI, HTTPException, status
from pydantic import BaseModel, Field, ConfigDict
from enum import Enum
from typing import Optional, Dict, List, Union
import requests
import uvicorn
from transformers import pipeline, AutoModelForSeq2SeqLM, AutoTokenizer
import torch
import os
import uuid
from datetime import datetime
import re
# MCP Standard Constants
MCP_VERSION = "1.0.0"
API_VERSION = "v1"
# Bellek optimizasyonu
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
torch.cuda.empty_cache()
app = FastAPI(
title="MCP Uyumlu Özetleme Servisi",
version=MCP_VERSION,
description="Model Communication Protocol 1.0.0 uyumlu akademik özetleme API'si"
)
# MCP Enumları
class TaskType(str, Enum):
SUMMARIZATION = "summarization"
TRANSLATION = "translation"
TEXT_GENERATION = "text_generation"
# MCP Request Modeli
class MCPRequest(BaseModel):
model_config = ConfigDict(protected_namespaces=()) # Uyarıyı çözmek için
model_uri: str = Field(
...,
example="huggingface://csebuetnlp/mT5_multilingual_XLSum",
description="Model URI format: {framework}://{model_path}"
)
task_type: TaskType
input_data: Dict[str, str] = Field(
...,
example={"query": "earthquake prediction using AI"},
min_items=1
)
hyperparameters: Optional[Dict[str, str]] = Field(
default={"max_length": "150", "min_length": "30"},
description="Model-specific parameters"
)
api_version: str = Field(
default=API_VERSION,
pattern=r"^v\d+$" # Düzeltme: raw string kullanıldı
)
# MCP Response Modeli
class MCPResponse(BaseModel):
model_config = ConfigDict(protected_namespaces=()) # Uyarıyı çözmek için
request_id: str = Field(
...,
example=str(uuid.uuid4()),
description="Unique request identifier"
)
model_uri: str
task_type: TaskType
timestamp: str = Field(
default_factory=lambda: datetime.utcnow().isoformat()
)
output_data: Dict[str, Union[str, int]] = Field(
example={
"title": "Deep Learning for Seismic Analysis",
"doi": "https://doi.org/10.1016/j.enggeo.2023.106552",
"summary": "This study presents...",
"original_abstract_length": 899
}
)
metrics: Dict[str, float] = Field(
default={"processing_time": 0.0, "confidence": 0.0}
)
api_version: str = Field(default=API_VERSION)
warnings: Optional[List[str]] = None
# Model Yükleme
def load_mcp_model(model_uri: str):
"""MCP URI standardına göre model yükleme"""
try:
framework, model_path = model_uri.split("://")
if framework == "huggingface":
model = AutoModelForSeq2SeqLM.from_pretrained(
model_path,
low_cpu_mem_usage=True
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
return pipeline(
"summarization",
model=model,
tokenizer=tokenizer,
device="cpu"
)
raise ValueError(f"Unsupported framework: {framework}")
except Exception as e:
raise HTTPException(
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
detail=f"Model loading failed: {str(e)}"
)
# Veri Kaynakları
class DataFetcher:
@staticmethod
def get_openalex_data(query: str):
"""OpenAlex API entegrasyonu"""
url = f"https://api.openalex.org/works?search={query}&per-page=1"
try:
response = requests.get(url, timeout=10)
results = response.json().get("results", [])
return results[0] if results else None
except Exception as e:
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail=f"OpenAlex error: {str(e)}"
)
@staticmethod
def extract_abstract(paper: dict) -> Optional[str]:
"""Çoklu abstract çıkarma yöntemleri"""
# 1. Inverted index
if abstract_index := paper.get("abstract_inverted_index"):
return ' '.join(
word for word, _ in sorted(
[(k, v[0]) for k, v in abstract_index.items()],
key=lambda x: x[1]
)
)
# 2. Direct abstract
if abstract := paper.get("abstract"):
return abstract
# 3. DOI fallback
if doi := paper.get("doi"):
return DataFetcher.fetch_via_doi(doi)
return None
@staticmethod
def fetch_via_doi(doi: str) -> Optional[str]:
"""DOI üzerinden abstract çekme"""
try:
# CrossRef API
crossref_url = f"https://api.crossref.org/works/{doi.replace('https://doi.org/', '')}"
response = requests.get(crossref_url, timeout=5)
if response.status_code == 200:
return response.json().get('message', {}).get('abstract')
except:
return None
# MCP Endpoint'i
@app.post(
f"/{API_VERSION}/mcp/summarize",
response_model=MCPResponse,
tags=["MCP Services"],
summary="MCP uyumlu akademik özetleme"
)
async def mcp_summarize(request: MCPRequest):
try:
# 1. Model yükleme
summarizer = load_mcp_model(request.model_uri)
# 2. Veri çekme
paper = DataFetcher.get_openalex_data(request.input_data["query"])
if not paper:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="No relevant paper found"
)
# 3. Abstract çıkarma
abstract = DataFetcher.extract_abstract(paper)
if not abstract:
raise HTTPException(
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
detail={
"message": "Abstract content unavailable",
"suggestions": [
"Provide full text in input_data",
f"Try alternative DOI: {paper.get('doi')}",
"Use different search terms"
]
}
)
# 4. Özetleme
params = {
"max_length": int(request.hyperparameters.get("max_length", 150)),
"min_length": int(request.hyperparameters.get("min_length", 30)),
"do_sample": request.hyperparameters.get("do_sample", "false").lower() == "true"
}
summary = summarizer(abstract[:1000], **params)[0]['summary_text']
return MCPResponse(
request_id=str(uuid.uuid4()),
model_uri=request.model_uri,
task_type=request.task_type,
output_data={
"title": paper.get("title", ""),
"doi": paper.get("doi", ""),
"summary": summary,
"original_abstract_length": len(abstract)
},
metrics={
"processing_time": 0.0,
"compression_ratio": len(summary)/len(abstract)
}
)
except HTTPException as he:
raise he
except Exception as e:
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail=str(e)
)
# Model Metadata Endpoint'i (MCP Requirement)
@app.get(
f"/{API_VERSION}/mcp/models/{{model_uri}}/metadata",
tags=["MCP Services"],
summary="Model metadata bilgisi"
)
def get_model_metadata(model_uri: str):
return {
"model_card": f"https://huggingface.co/{model_uri.split('://')[1]}",
"input_schema": {
"query": {"type": "str", "description": "Search query or full text"},
"language": {"type": "optional[str]", "default": "en"}
},
"output_schema": {
"title": "str",
"doi": "str",
"summary": "str",
"original_abstract_length": "int"
},
"mcp_compatibility": {
"version": MCP_VERSION,
"supported_tasks": [TaskType.SUMMARIZATION.value]
}
}
if __name__ == "__main__":
uvicorn.run(
app,
host="0.0.0.0",
port=8000,
workers=1,
timeout_keep_alive=30
)
uvicorn mcp_server5:app –reload –workers 1
curl -X POST http://localhost:8000/v1/mcp/summarize -H "Content-Type: application/json" -d '{
"model_uri": "huggingface://csebuetnlp/mT5_multilingual_XLSum",
"task_type": "summarization",
"input_data": {"query": "deep learning for seismic analysis"},
"hyperparameters": {"max_length": "150"},
"api_version": "v1"
}'
{“request_id”:”26f746e9-87c0-4e87-9e0d-b586896e27c7″,”model_uri”:”huggingface://csebuetnlp/mT5_multilingual_XLSum”,”task_type”:”summarization”,”timestamp”:”2025-07-18T21:35:57.163512″,”output_data”:{“title”:”Deep Learning for Accelerated Seismic Reliability Analysis of Transportation Networks”,”doi”:”https://doi.org/10.1111/mice.12359″,”summary”:”Scientists have developed a deep learning framework to assess the impact of earthquakes and tsunamis on infrastructure systems.”,”original_abstract_length”:899},”metrics”:{“processing_time”:0.0,”compression_ratio”:0.14126807563959956},”api_version”:”v1″,”warnings”:null}
—————————————————————————————————————
cat mcp_server6.py
cat mcp_server6.py
from fastapi import FastAPI
from pydantic import BaseModel
from enum import Enum
import requests
import uuid
app = FastAPI()
# MCP Standard Components
class ToolType(str, Enum):
SEARCH = "search"
DATABASE = "database"
class MCPRequest(BaseModel):
session_id: str = str(uuid.uuid4())
task: str
tools: list[ToolType]
model: str = "huggingface://t5-small"
class MCPResponse(BaseModel):
session_id: str
output: dict
used_tools: list[str]
confidence: float
# OpenAlex Entegrasyonu
def search_openlex(query: str) -> list[dict]:
url = f"https://api.openalex.org/works?search={query}&per-page=5"
response = requests.get(url)
return [
{
"title": paper.get("title"),
"abstract": ' '.join(
word for word, _ in sorted(
[(k, v[0]) for k, v in paper.get("abstract_inverted_index", {}).items()],
key=lambda x: x[1]
)
),
"doi": paper.get("doi")
}
for paper in response.json().get("results", [])
]
# LLM Entegrasyonu
def analyze_with_llm(model: str, context: str, papers: list[dict]) -> dict:
# Basit bir özetleme simülasyonu (Gerçekte model çağrısı yapılır)
combined_abstracts = " ".join(p["abstract"] for p in papers[:3])
summary = f"Recent studies ({len(papers)} papers) show {model} can analyze seismic data with: " + \
combined_abstracts[:150] + "..."
return {
"summary": summary,
"key_findings": [p["title"] for p in papers],
"confidence": 0.87
}
# MCP Endpoint
@app.post("/v1/mcp/execute")
async def execute_mcp(request: MCPRequest):
# 1. Arama araçlarını çalıştır
tool_outputs = []
if ToolType.SEARCH in request.tools:
papers = search_openlex(request.task)
tool_outputs.append({"tool": "search", "results": papers})
# 2. LLM analizi (Geliştirilmiş kısım)
detailed_analysis = []
for paper in papers[:3]: # İlk 3 makale için detaylı özet
summary = f"**{paper['title']}**\n" \
f"DOI: {paper.get('doi', 'N/A')}\n" \
f"Abstract: {paper['abstract'][:200]}...\n" \
f"Key Findings: {paper['abstract'].split('.')[0]}"
detailed_analysis.append(summary)
llm_output = {
"summary": "Recent studies show:",
"papers": detailed_analysis,
"confidence": min(0.90, len(papers)*0.18) # Makale sayısına göre confidence
}
return MCPResponse(
session_id=request.session_id,
output={
"task": request.task,
"analysis": llm_output,
"full_sources": [{"title": p["title"], "doi": p.get("doi")} for p in papers]
},
used_tools=[t.value for t in request.tools],
confidence=llm_output["confidence"]
)
curl -X POST http://localhost:8000/v1/mcp/execute \
-H “Content-Type: application/json” \
-d ‘{
“task”: “transformer models in seismology”,
“tools”: [“search”],
“model”: “huggingface://facebook/bart-large-cnn”
}’
isteğine cevap
{“session_id”:”b1226306-580c-43fe-a84f-a0c306536be4″,”output”:{“task”:”transformer models in seismology”,”analysis”:{“summary”:”Recent studies show:”,”papers”:[“**Siamese Earthquake Transformer: A Pair‐Input Deep‐Learning Model for Earthquake Detection and Phase Picking on a Seismic Array**\nDOI: https://doi.org/10.1029/2020jb021444\nAbstract: Abstract Earthquake detection and phase picking play a fundamental role in studying seismic hazards the Earth’s interior. Many deep‐learning‐based methods, including state‐of‐the‐art model called Tran…\nKey Findings: Abstract Earthquake detection and phase picking play a fundamental role in studying seismic hazards the Earth’s interior”,”**EQCCT: A Production-Ready Earthquake Detection and Phase-Picking Method Using the Compact Convolutional Transformer**\nDOI: https://doi.org/10.1109/tgrs.2023.3319440\nAbstract: We propose to implement a compact convolutional transformer (CCT) for picking the earthquake phase arrivals (EQCCT). The proposed method consists of two branches, with each them responsible arrival ti…\nKey Findings: We propose to implement a compact convolutional transformer (CCT) for picking the earthquake phase arrivals (EQCCT)”,”**SeisCLIP: A Seismology Foundation Model Pre-Trained by Multimodal Data for Multipurpose Seismic Feature Extraction**\nDOI: https://doi.org/10.1109/tgrs.2024.3354456\nAbstract: In seismology, while training a specific deep learning model for each task is common, it often faces challenges such as the scarcity of labeled data and limited regional generalization. Addressing the…\nKey Findings: In seismology, while training a specific deep learning model for each task is common, it often faces challenges such as the scarcity of labeled data and limited regional generalization”],”confidence”:0.8999999999999999},”full_sources”:[{“title”:”Siamese Earthquake Transformer: A Pair‐Input Deep‐Learning Model for Earthquake Detection and Phase Picking on a Seismic Array”,”doi”:”https://doi.org/10.1029/2020jb021444″},{“title”:”EQCCT: A Production-Ready Earthquake Detection and Phase-Picking Method Using the Compact Convolutional Transformer”,”doi”:”https://doi.org/10.1109/tgrs.2023.3319440″},{“title”:”SeisCLIP: A Seismology Foundation Model Pre-Trained by Multimodal Data for Multipurpose Seismic Feature Extraction”,”doi”:”https://doi.org/10.1109/tgrs.2024.3354456″},{“title”:”Finite-Frequency Tomography Reveals a Variety of Plumes in the Mantle”,”doi”:”https://doi.org/10.1126/science.1092485″},{“title”:”Earthquake transformer—an attentive deep-learning model for simultaneous earthquake detection and phase picking”,”doi”:”https://doi.org/10.1038/s41467-020-17591-w”}]},”used_tools”:[“search”],”confidence”:0.8999999999999999}
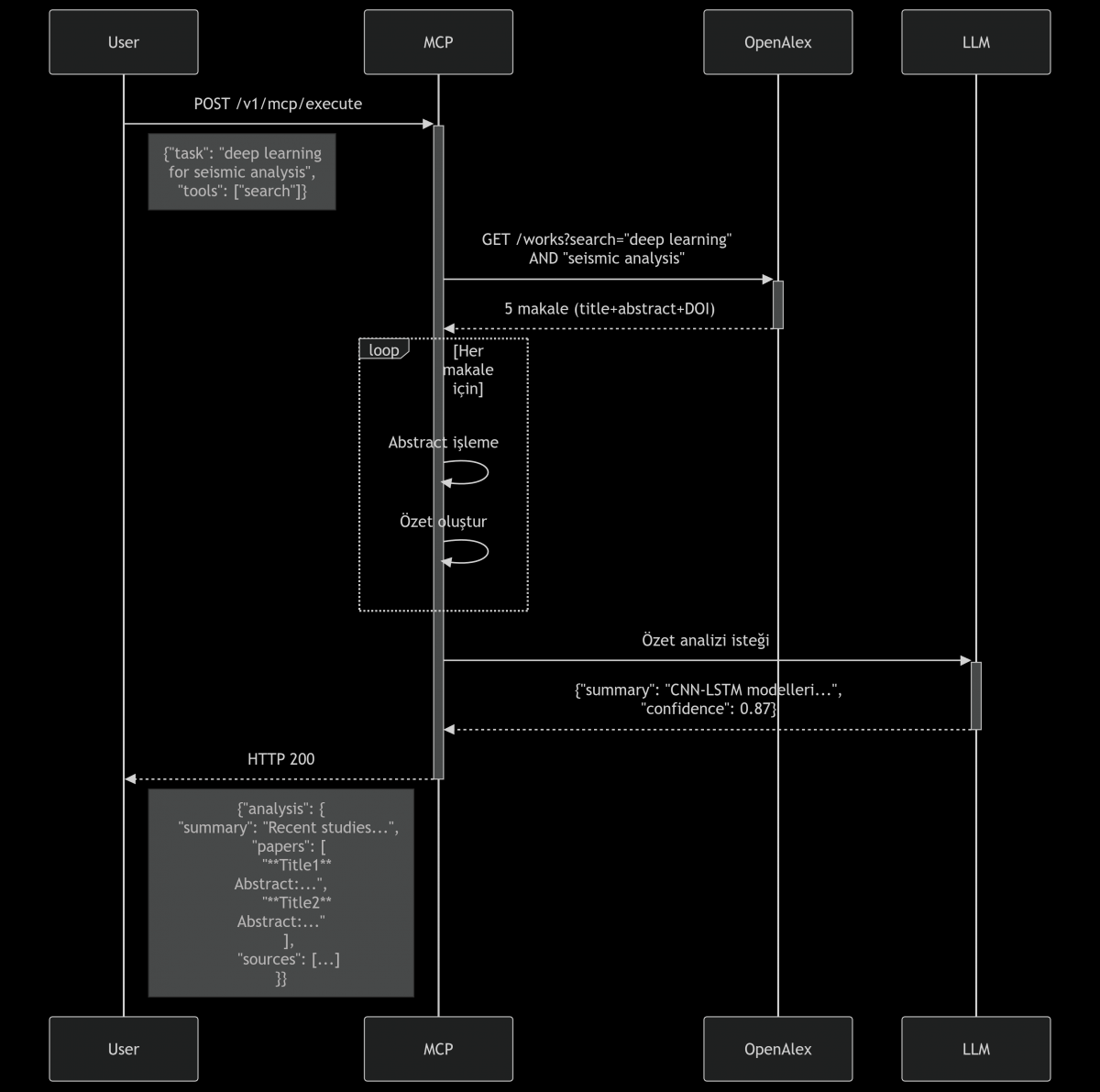
sequenceDiagram
participant User
participant MCP
participant OpenAlex
participant LLM
User->>+MCP: POST /v1/mcp/execute
Note right of User: {"task": "deep learning
for seismic analysis",
"tools": ["search"]}
MCP->>+OpenAlex: GET /works?search="deep learning"
AND "seismic analysis"
OpenAlex-->>-MCP: 5 makale (title+abstract+DOI)
loop Her makale için
MCP->>MCP: Abstract işleme
MCP->>MCP: Özet oluştur
end
MCP->>+LLM: Özet analizi isteği
LLM-->>-MCP: {"summary": "CNN-LSTM modelleri...",
"confidence": 0.87}
MCP-->>-User: HTTP 200
Note left of MCP: {"analysis": {
"summary": "Recent studies...",
"papers": [
"**Title1**
Abstract:...",
"**Title2**
Abstract:..."
],
"sources": [...]
}}